今回は、streamlitのchat_inputにファイルアップロード機能が追加され、マルチモーダルチャットボットを作成できるようになったため、確認していきます。
実際に、ファイルアップロード機能を使用したチャットボットも作成してみたので併せてみてもらえればと思います。
では早速確認していきましょう。
パラメータの確認
streamlitのリリースノートを確認すると、version 1.43.0(March 4, 2025)からst.chat_inputにファイルアップロード機能が追加されたようです。
このアップデートにより、streamlitを使用して、マルチモーダルチャットアプリが作成できるようになりました。
今回のファイルアップロード機能で追加されたパラメータについて確認しておきます。
| パラメータ | 説明 |
| accept_file | ファイルの受け入れを有効にするかどうかを指定します。 デフォルト: False True: 1つのファイルを受け入れます。 “multiple”: 複数のファイルを受け入れます。 |
| file_type | 許可するファイルの拡張子を指定します。 文字列: 単一のファイル拡張子を許可します(例: “csv”)。 リスト: 複数のファイル拡張子を許可します(例: [“jpg”, “jpeg”, “png”])。 |
詳細:streamlit公式ドキュメント(st.chat_input)
サンプルコードの確認
st.chat_inputのアップロード機能を使用したサンプルコードを確認します。
1つのファイルのみをアップロードする設定を行った場合は、以下の結果になりました。
import streamlit as st
prompt = st.chat_input(
"Say something and/or attach an image",
accept_file=True,
file_type=["jpg", "jpeg", "png"],
)
if prompt and prompt.text:
st.markdown(prompt.text)
# 1枚の画像を選択した場合、画像を表示する
if prompt and prompt["files"]:
st.image(prompt["files"][0])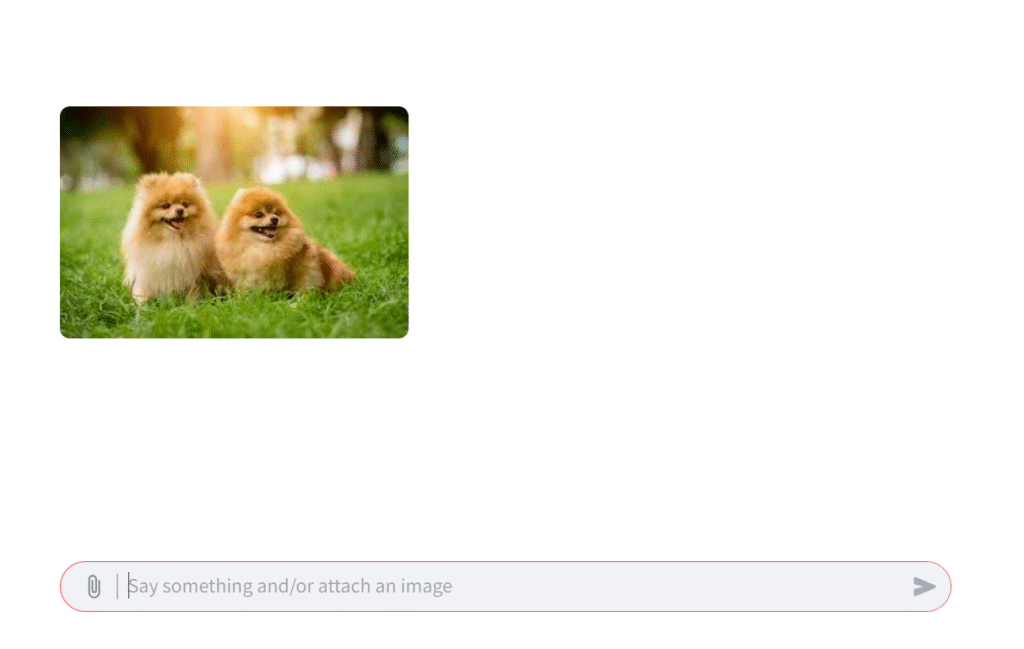
次に、複数ファイル選択できるようにした場合は、以下のようになりました。
accept_file=”multiple”にすることで、ファイル選択時、複数ファイルを選択することができるようです。
import streamlit as st
prompt = st.chat_input(
"Say something and/or attach an image",
accept_file="multiple",
file_type=["jpg", "jpeg", "png"],
)
if prompt and prompt.text:
st.markdown(prompt.text)
# 複数の画像を選択した場合、画像を表示する
if prompt and prompt["files"]:
for file in prompt["files"]:
st.image(file)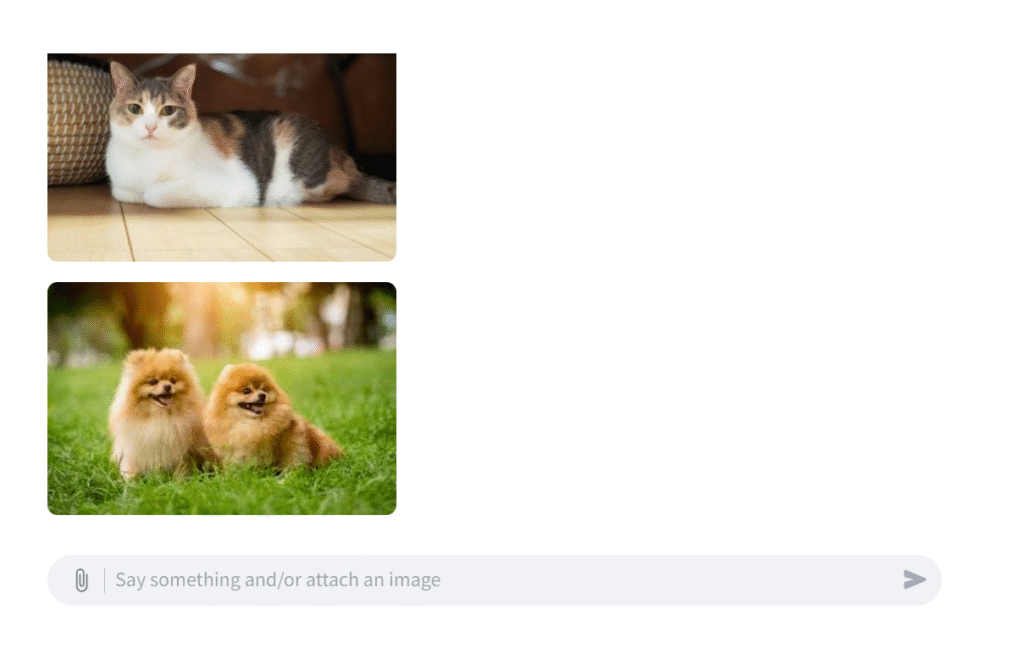
マルチモーダルチャットボットの作成
最後に、今回追加されたファイルアップロード機能を使用して、マルチモーダルなチャットボットを作成していきます。
streamlitのchta_input機能を用いたチャットボットの作成方法詳細については、以下の記事を参考にしてください。

まずは完成版のコードです。
import streamlit as st
import openai
import os
import base64
from dotenv import load_dotenv
# 環境変数を読み込む
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
st.title("ChatGPT Chatbot with Images")
# セッション状態初期化
if "chat_history" not in st.session_state:
st.session_state.chat_history = []
# 履歴の描画
for msg in st.session_state.chat_history:
with st.chat_message(msg["role"]):
if msg["type"] == "text":
st.write(msg["content"])
else:
st.image(msg["content"])
# テキスト & 画像を同時に受け付ける
prompt = st.chat_input(
"質問を入力してください(テキスト & 画像複数可)",
accept_file="multiple",
file_type=["jpg", "jpeg", "png"],
)
if prompt:
# 1) テキストを履歴に追記
if prompt.text:
st.session_state.chat_history.append({
"role": "user",
"type": "text",
"content": prompt.text
})
with st.chat_message("user"):
st.markdown(prompt.text)
# 2) 画像ファイルを履歴に追記
for img in prompt.files or []:
st.session_state.chat_history.append({
"role": "user",
"type": "image",
"content": img # keep the UploadedFile for display
})
with st.chat_message("user"):
st.image(img)
# 3) OpenAI に渡す messages を組み立て
messages = []
# system プロンプトなど必要ならここで追加
for msg in st.session_state.chat_history:
if msg["type"] == "text":
messages.append({
"role": msg["role"],
"content": msg["content"]
})
else:
# 画像の場合は content をリストにして渡す
# Base64 でも URL でも可。ここでは Data URL を使う例
img_bytes = msg["content"].read()
msg["content"].seek(0)
data64 = base64.b64encode(img_bytes).decode("ascii")
data_url = f"data:{msg['content'].type};base64,{data64}"
messages.append({
"role": msg["role"],
"content": [
{"type": "text", "text": ""},
{"type": "image_url", "image_url": {
"url": data_url
}}
]
})
# 4) ストリーミングで API 呼び出し
response = openai.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
stream=True
)
# 5) 応答を逐次表示+履歴に保存
full_resp = ""
with st.chat_message("assistant"):
placeholder = st.empty()
for chunk in response:
delta = chunk.choices[0].delta.content
if delta:
full_resp += delta
placeholder.markdown(full_resp)
placeholder.markdown(full_resp)
st.session_state.chat_history.append({
"role": "assistant",
"type": "text",
"content": full_resp
})
以下順にコードの解説を行います。
ライブラリのインポート及び環境変数の読み込み
import streamlit as st
import openai
import os
import base64
from dotenv import load_dotenv
# .env ファイルから環境変数を読み込む
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")まず、必要なライブラリの読み込み、及び環境変数の読み込みを行います。
環境変数は.envファイルに保存されているOPENAI_API_KEYを読み込むようにしています。
タイトル表示とセッション状態の初期化
st.title("ChatGPT Chatbot with Images")
if "chat_history" not in st.session_state:
# セッションごとにチャット履歴を保持するリストを作る
st.session_state.chat_history = []st.title でタイトルを表示しています。
st.session_stateを用意し、最初のアクセス時だけ chat_history(チャット履歴)を空リストで作成します。
過去のやりとりを画面に描画
for msg in st.session_state.chat_history:
with st.chat_message(msg["role"]):
if msg["type"] == "text":
st.write(msg["content"])
else:
st.image(msg["content"])for ループ で、これまで送受信したメッセージを順番に画面に描画します。
msg[“role”] が “user” か “assistant” で表示表示が自動で切り替わります。
msg[“type”] が “text” → st.write、”image” → st.image を使い分けています。
ユーザー入力部:テキスト+複数画像
prompt = st.chat_input(
"質問を入力してください(テキスト & 画像複数可)",
accept_file="multiple",
file_type=["jpg", "jpeg", "png"],
)st.chat_inputにてテキスト入力に加え、accept_file=”multiple” で複数ファイル(ここでは画像)を同時にアップロードできるようにしています。
ユーザーの発言をチャット履歴に追加し表示
if prompt:
# テキスト部分があれば
if prompt.text:
st.session_state.chat_history.append({
"role": "user", "type": "text", "content": prompt.text
})
with st.chat_message("user"):
st.markdown(prompt.text)
# 画像ファイルがあれば
for img in prompt.files or []:
st.session_state.chat_history.append({
"role": "user", "type": "image", "content": img
})
with st.chat_message("user"):
st.image(img)
テキスト入力があれば “text” タイプで履歴に保存し、画面に表示しています。
画像ファイルが存在するのであれば、アップロードされた UploadedFile オブジェクトを “image” タイプで履歴に保存し、画面には st.image で表示しています。
OpenAI API 用の messages を組み立てる
messages = []
for msg in st.session_state.chat_history:
if msg["type"] == "text":
messages.append({
"role": msg["role"],
"content": msg["content"]
})
else:
# 画像は Data URL に変換して、要素リストとして渡す
img_bytes = msg["content"].read()
msg["content"].seek(0)
data64 = base64.b64encode(img_bytes).decode("ascii")
data_url = f"data:{msg['content'].type};base64,{data64}"
messages.append({
"role": msg["role"],
"content": [
{"type": "text", "text": ""},
{"type": "image_url", "image_url": {"url": data_url}}
]
})テキストについては、そのまま、”content”に値を入れてmessagesに追加します。
画像については、UploadedFile をバイト列に読み出しし、Base64 にエンコードして Data URL化を行います。そのうえで、Chat API の仕様に沿い、リスト [text 要素, image_url 要素] の形で渡しています。
Chat Completions API の呼び出しとストリーミング表示
response = openai.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
stream=True
)
full_resp = ""
with st.chat_message("assistant"):
placeholder = st.empty()
for chunk in response:
delta = chunk.choices[0].delta.content
if delta:
full_resp += delta
placeholder.markdown(full_resp)
placeholder.markdown(full_resp)
st.session_state.chat_history.append({
"role": "assistant", "type": "text", "content": full_resp
})最後に、APIの呼び出しを行い、ストリーミング表示を行っています。
最終的な全文を st.session_state.chat_history に保存しています。
コードを実行した結果がこちらになります。
まとめ
streamlit chat_inputのファイルアップロード機能を確認しました。
これで、streamlitでも画像を用いたマルチモーダルなアプリ作成ができるようになりました。
streamlitとChatGPTAPIを用いることで簡単にChatBot Webアプリ作成が可能となるため、ぜひ試してください。