
近年、AIチャットボットや類似文章検索など、自然言語を扱う技術が急速に進化しています。その中心的な役割を果たしている技術が、「text-embedding(テキスト埋め込み)」です。
本記事では、OpenAIが提供するtext-embedding APIの仕組みや使い方について見ていきます。
text-embeddingの概要
「テキスト埋め込み(text embedding)」とは、文章や単語といったテキスト情報をベクトル(数値の並び)に変換する技術のことです。
これによって、言葉の意味や関係性をコンピュータが理解しやすい形で扱えるようになります。
人間にとって「猫」と「犬」は似たような動物だと直感的にわかりますが、コンピュータにはそれがわかりません。
そこで、各単語や文章を数値の形(たとえば「[0.12, -0.83, 0.45, …]」のようなベクトル)に変換することで、「意味の近さ」や「文脈の違い」を計算できるようになります。
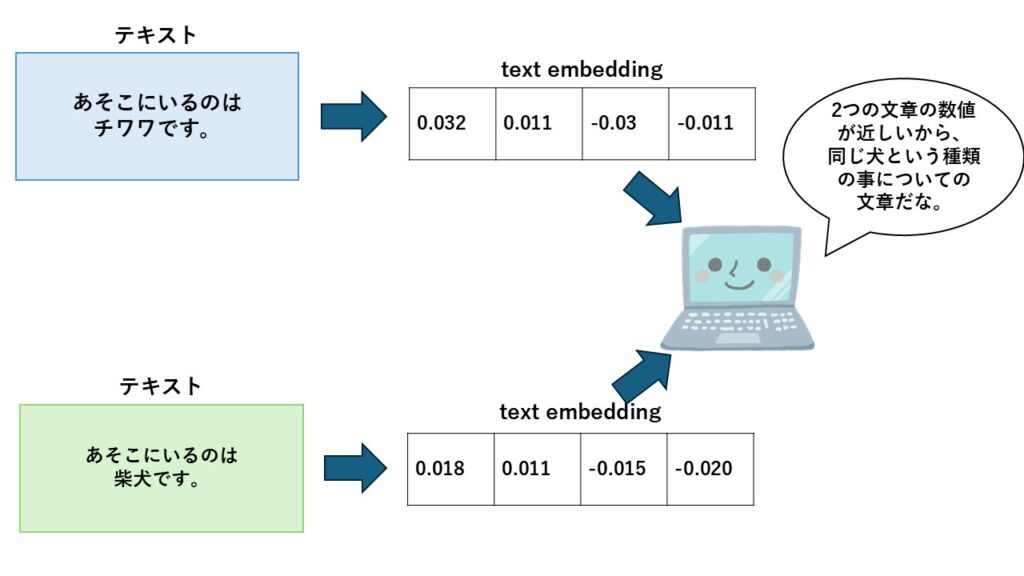
このベクトル同士の距離を使うことで、以下のようなことが可能になります。
- 似ている文章を見つける(類似検索)
- 質問と回答を関連付ける(QAシステム)
- 文章の分類やクラスタリング
OpenAIが提供しているtext-embeddingについても同じ仕組みで、それを、誰でもAPI経由で簡単に使えるようにしてくれています。
OpenAIのtext-embeddingについて
それでは、OpenAIのtext-embeddingについて、代表的なモデルとその特徴について紹介します。
text-embeddingの種類
OpenAIのtext-embeddingで現在利用できる主なモデルは以下の通りです。
| モデル名 | 精度 | 速度 | コスト | 特徴 |
| text-embedding-ada-002 | 低い | 非常に速い | 安い | 期に登場したモデルで、非常に高速かつ低コスト。 |
| text-embedding-3-small | 中 | 早い | やや高い | ada-002より高性能で、コストも安い。高速処理向け。 |
| text-embedding-3-large | 高い | 普通 | 安い | 現時点で最も精度が高いモデル。意味の理解力が高い。 |
現在点でお試しで実行する場合は、text-embedding-3-smallから試すことを推奨します。
料金体系
OpenAIのtext-embedding APIは、「入力するテキストの長さ(トークン数)」に応じて料金が発生します。
トークンとは、文章を分割した単位のことで、日本語でも英語でも一定の文字数ごとに1トークンとしてカウントされます。
| モデル名 | 価格(1Mトークンあたり) |
| text-embedding-3-small | $0.02 |
| text-embedding-3-large | $0.13 |
| text-embedding-ada-002 | $0.10 |
例えば、500文字程度の文章(約100〜150トークン)をtext-embedding-3-smallで処理すると、0.000002〜0.000003ドル程度のコストしかかかりません。
text-embedding-3の使い方
ここでは、OpenAIが提供する最新版のベクトル化モデル text-embedding-3 を使って、実際にテキストをベクトル(embedding)に変換する方法を紹介します。
まずは、全体のコードです。
import os
from openai import OpenAI
from dotenv import load_dotenv
# .envファイルからAPIキーを読み込む
load_dotenv()
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
)
# ベクトルに変換したいテキスト
input_text = "こんにちは。今日はいい天気ですね。"
# embedding取得
response = client.embeddings.create(
model="text-embedding-3-small",
input=input_text,
dimensions=1536
)
# 結果のベクトルを取得
embedding_vector = response.data[0].embedding
# 結果の確認(最初の10個だけ表示)
print(embedding_vector[:10])では順にコードの解説をします。
必要ライブラリの読み込みと環境変数の設定
import os
from openai import OpenAI
from dotenv import load_dotenv
# .envファイルからAPIキーを読み込む
load_dotenv()
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
)必要なライブラリの読み込みと、.envファイルに保存したOpenAIのAPIキーを読み込んで、api_key変数に代入しています。
そして、APIにアクセスするための「クライアント」を作成しています。
テキストをベクトルに変換
# embedding取得
response = client.embeddings.create(
model="text-embedding-3-small",
input=input_text,
dimensions=1536
)model=”text-embedding-3-small”:使いたいモデルを指定します。
input=input_text:ベクトルに変換したい文章をここで指定します。
dimensions=1536:ベクトルの次元数を指定します。
ベクトルを取得・表示
# 結果のベクトルを取得
embedding_vector = response.data[0].embedding
# 結果の確認(最初の10個だけ表示)
print(embedding_vector[:10])APIの応答から、実際のベクトル(数値の並び)を取り出します。
全てを表示すると1536次元で非常に長くなるため、今回は最初の10件を取り出しています。
結果は以下のように表示されました。
[0.01778455264866352, -0.013280457817018032, -0.052360109984874725, 0.028365865349769592, 0.09531460702419281, -0.007037648931145668, -0.019937245175242424, -0.009653998538851738, -0.02531897835433483, 0.005067107267677784]text-embeddingを使用した文章比較
最後に、text-embeddingを使用した文章比較を行います。
テキストがembedding(ベクトル)に変換されると、各文章が「数値の点」として表現されます。
すると、それぞれの文章のベクトル同士の距離を計算することで、意味が近いかどうかを判定できます。
この「距離」を測る方法としてよく使われるのが、コサイン類似度(cosine similarity)です。
コサイン類似度を用いた文書比較のコードです。
import os
import numpy as np
from openai import OpenAI
from dotenv import load_dotenv
from numpy.linalg import norm
# 類似度を計算する関数(コサイン類似度)
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (norm(vec1) * norm(vec2))
# 環境変数からAPIキーを読み込み
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=api_key)
# 比較する文章(似ているかどうか確認してみよう)
text1 = "今日はとても天気が良いです。"
text2 = "今日は晴天です。"
# 2つの文章をembedding化
response = client.embeddings.create(
model="text-embedding-3-small",
input=[text1, text2],
dimensions=1536
)
vec1 = response.data[0].embedding
vec2 = response.data .embedding
# 類似度を計算
similarity = cosine_similarity(vec1, vec2)
print(f"文章の類似度:{similarity:.4f}")
.embedding
# 類似度を計算
similarity = cosine_similarity(vec1, vec2)
print(f"文章の類似度:{similarity:.4f}")
コサイン類似度を計算する関数「cosine_similarity」を用意し、2つの文章のコサイン類似度を similarity = cosine_similarity(vec1, vec2) で計算しています。
結果は以下の通りになりました。
2つの文章は、似た意味の文章であるため、類似度は高く出ています。
文章の類似度:0.7729テキストを全く似ていない文章に変更して実行します。
text1 = "今日はとても天気が良いです。"
text2 = "あそこにいるのは犬です。"結果は以下の通りです。
2つの文章は、異なる意味の文章のため、類似度は低く出ています。
文章の類似度:0.2410以上のように、embeddingを使うと、文章の意味的な距離を数値で評価できるようになります。
類似検索チャットボットやQAチャットボットは、この仕組みを生かして作成しています。
まとめ
今回は、OpenAIのtext-embedding APIについて解説しました。
text-embeddingは、文章の意味を数値で表現できる技術で、特にRAG(検索拡張生成)システムの構築には欠かせない要素です。
類似文の検索や意味の比較が簡単にできるため、FAQ自動応答や社内ナレッジ検索など、実用的なシーンで幅広く活用されています。
今後、DXが進む中で、こうした技術を活用したチャットボットやQAシステムの需要はますます高まっていくと考えられます。
今のうちに理解を深めておくことが重要です。





