
今回は、OpenAI Vector Storeを使用したRAGシステムの構築について見ていきます。
RAGシステム構築においては、ベクトルデータベースが必要となります。
また、検索対象のデータのベクトル化も必要となります。
それらを、ひとまとめに実行できるのが、OpenAIのVector Storeになります。
それでは早速見ていきましょう。
OpenAI Vector Storeの特徴
ChatGPTをさらに賢く使うために注目されているのが「RAG」という仕組みです。
RAGを実現するために欠かせないのが「ベクトルストア(Vector Store)」という技術になります。
OpenAIは2024年に独自のVector Store機能を提供開始しました。
この機能を使うことで、ChatGPTと外部の文書データを連携させ、ユーザーの質問に対してより正確で文脈に沿った回答を出すことができます。
OpenAIのVector Storeは、以下の4点の特徴があります。
- OpenAIのエコシステムとシームレスに連携
- 埋め込みモデルが最適化済み
- データのセキュアな取り扱いが可能
- 高い検索精度と拡張性
順に確認していきます。
OpenAIのエコシステムとシームレスに連携
OpenAI Vector Storeの最大の魅力は、ChatGPTやEmbedding API、ChatCompletionなどの他のOpenAIサービスとスムーズに連携できることです。
これにより、複雑なデータ連携やサードパーティ製ツールの設定を行うことなく、すべてOpenAIのエコシステム内で完結したRAGシステムを構築できます。
例えば、以下のような流れで簡単にRAG構築ができます。
1.OpenAI Vector Storeへの文書をアップロード
2.ベクトルストアに文書を登録して埋め込み
3.ユーザーの質問をベクトル検索
4.ChatGPTに検索結果を渡して回答生成
OpenAI Vector Storeを使わずにRAGを構築しようとした場合、ベクトルDBを構築し、運用していく必要があります。
その点、OpenAI Vector Storeであれば、OpenAIツール内で完結できるので非常に便利です。
埋め込みモデルが最適化済み
OpenAIのVector Storeでは、文書を検索可能な形式に変換するために「埋め込み(embedding)」という処理を行います。
このとき使われるのが、OpenAIが提供するtext-embedding-3シリーズのモデルです。
OpenAIのtext-embeddingについては、以下の参考にしてください。
embeddingモデルは、RAGをはじめとする検索・分類・類似度判定のタスクに最適化されており、以前のtext-embedding-ada-002よりも精度・圧縮率・コストの面で大きく進化しています。
Vector Storeを使用することで、ファイルをアップロードするだけで、embedding処理を行ってくれます。
データのセキュアな取り扱い
OpenAI Vector Storeでは、アップロードされたファイルや生成されたベクトル情報が厳重なセキュリティ管理のもとで保管されます。
OpenAI Vector Storeでアップロードされたデータは、OpenAI社のセキュアなクラウドインフラ上で暗号化されて管理されます。転送時にはHTTPS(TLS)による暗号化が行われており、外部からの盗聴や改ざんを防ぐ仕組みが整っています。
また、ユーザーがアップロードしたデータや生成されたベクトルは、OpenAIの明示的なポリシーによりモデルのトレーニングには利用されません。これにより、業務データや社内資料を安心して活用できます。
また、アップロードされたドキュメントやベクトルデータは、ユーザー自身で明示的に削除することができます。
たとえば以下のように簡単に削除できます。
client.vector_stores.delete(vector_store_id)高い検索精度と拡張性
OpenAI Vector Storeは、ユーザーの質問に対してより意味的に近い文書を高精度で取得できる検索機能を持っています。
また、OpenAI Vector Storeの設計は柔軟性があり、「新しいファイルの追加」「用途ごとのストア分割」も可能となっています。
ドキュメントのアップロードとベクトル化
では実際に、ドキュメントをOpenAI Vector Storeにアップロードし、ベクトルデータベースを作成する手順を確認します。
データ準備
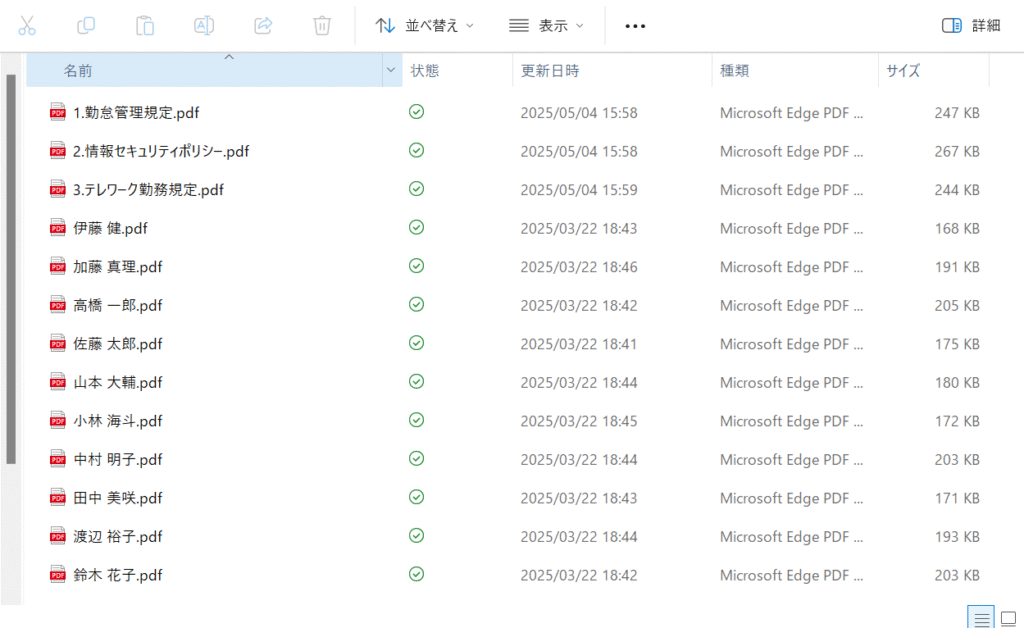
データアップロード行うドキュメントを準備します。
今回アップロードするドキュメントとしては、2種類のPDFファイルを用意しました。
1つは仮の社員情報です。

2つ目は仮の社内規定です。

全部で13ファイル用意し、それをアップロード、ベクトル化します。
ベクトルデータベース作成
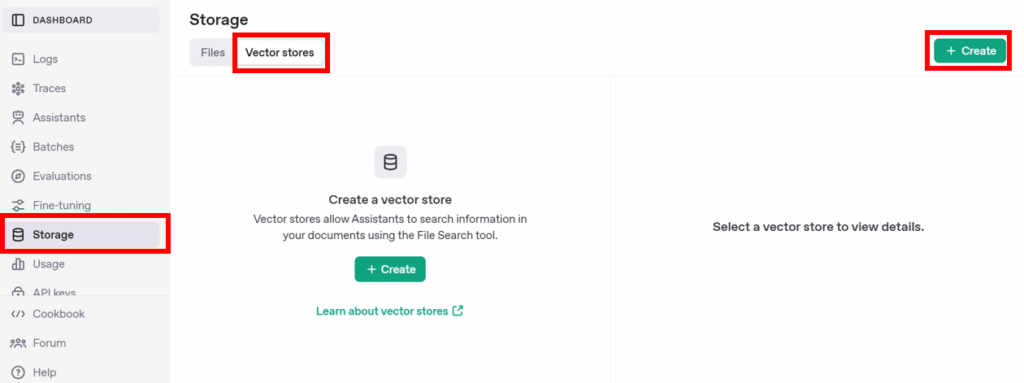
OpenAIのダッシュボードから「Strage」を選択します。
「Files」を選択し、「Vector stores」を選択し、「Create」を押します。
ファイル名をつけ、「Add files」を選択します。
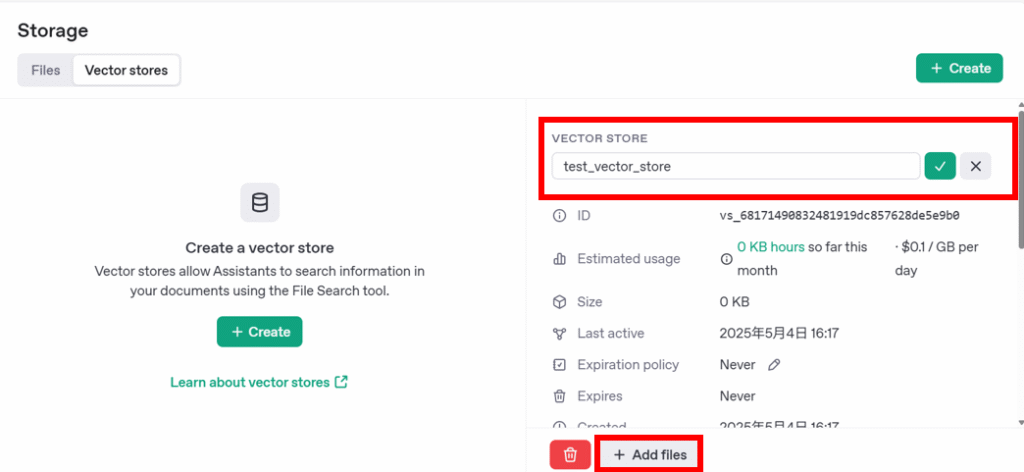
追加するファイルを選択する画面が出てきます。
ここで今回するファイルをすべてドラッグ&ドロップで移動させます。
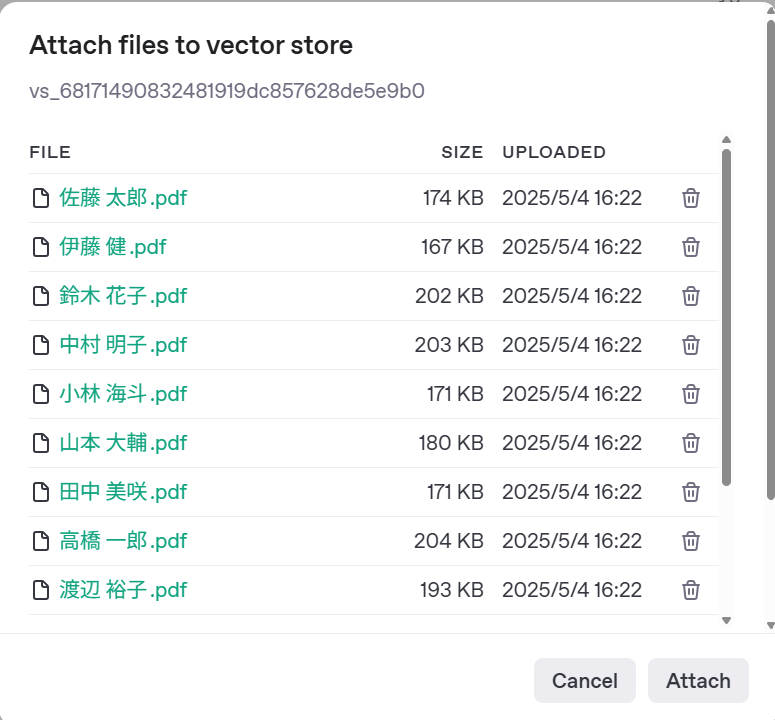
Attachを押すと、ベクトルデータベースが作成されます。
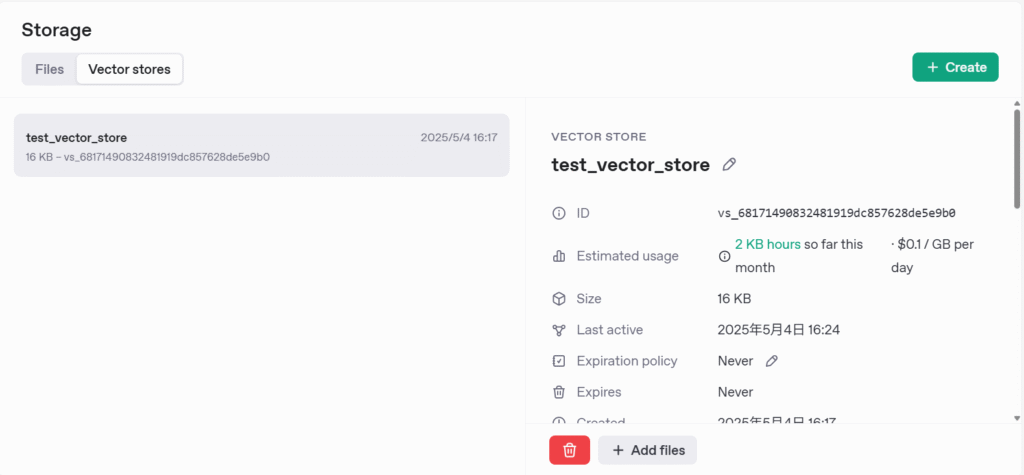
これで、ドキュメントのアップロードおよびベクトル化は完了です。
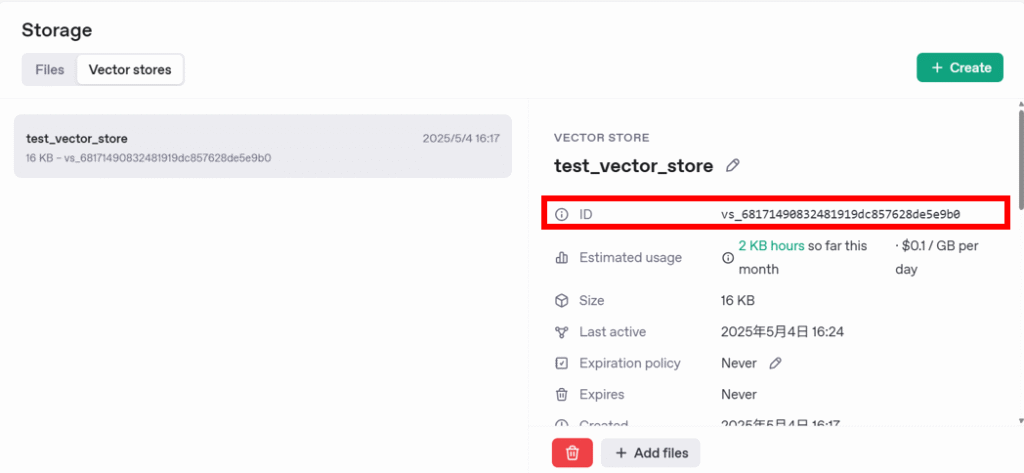
OpenAI Vector Storeでは、それぞれのベクトルDBごとにIDが振られます。
このIDを指定することで、対象のDBを操作することができるようになります。
ベクトルDBの費用について
ファイルストレージを使用すると、保管期間に応じた費用が発生します。
| 項目 | 内容 |
|---|---|
| ストレージ料金 | $0.10 / 1GB・月 (最初の1GBは無料) |
| 保管期間 | 使用しない限り保存され続ける(手動で削除可能) |
ベクトルDBを作成して、置いておくだけでも費用が発生していきますので、不要となったベクトルDBは削除するようにしましょう。
また、アップロードするファイルについては、文書量についても注意するようにしましょう。
ユーザーの質問に対する検索と回答生成
文書をアップロード・ベクトル化したら、ユーザーの質問に対して「RAG(」を実行できる状態になります。
ここでは、先ほど作成したベクトルDBを使って関連文書を検索し、ChatGPTと連携して自然な回答を生成する一連の流れを見ていきます。
vector_store.query() で関連文書を取得
まずは、ユーザーからの質問に対して、ベクトルストアから意味的に近い文書のを取得します。
from dotenv import load_dotenv
# .env ファイルを読み込む
load_dotenv()
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
)上記コードでまず、OpenAIのAPIキーの設定およびライブラリのインポートを行います。
search_results = client.vector_stores.search(
vector_store_id="xxxxxxx",
query="この会社の勤務時間について教えてください。",
)vector_store_idに今回作成したベクトルDBのIDを設定します。
そして、質問したい内容をqueryに記載します。
結果として、以下のようなデータを取得できます。
SyncPage[VectorStoreSearchResponse](
data=[
VectorStoreSearchResponse(
attributes={},
content=[
Content(
text="本社における全社員の勤務時間は原則として、・・・",
type="text",
)
],
file_id="file-H5CLJ9hFHCweS9AJyBrXbK",
filename="1.勤怠管理規定.pdf",
score=0.6712175891418474,
),
・・・
],
object="vector_store.search_results.page",
search_query=["この会社の休暇制度について教えて"],
has_more=False,
next_page=None,
)質問→検索→回答生成までのコードフロー
では、質問→検索した文書をChatGPTに回答を生成させるコードを確認します。
def answer_with_rag(client, vector_store_id, user_query):
# Step 1: 類似文書の検索
search_results = client.vector_stores.search(
vector_store_id= vector_store_id,
query=user_query,
)
# Step 2: 検索結果をまとめる
context_text = "\n\n".join([item.content[0].text for item in search_results.data])
# Step 3: ChatGPTに回答させる
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "以下の情報を参考に質問に答えてください。"},
{"role": "user", "content": f"情報:\n{context_text}\n\n質問: {user_query}"}
]
)
return response.choices[0].message.content
answer = answer_with_rag(client, "xxxx", "この会社の勤務時間について教えてください。")
print(answer)Step2に、ファイル検索した結果をテキストにまとめ、それをStep3にて、情報としてChatGPTに渡しています。
そうすることで、ChatGPTは渡された情報から、ユーザの質問の回答となる情報を探し、回答を生成することになります。
結果としては、以下のようにかえってきました。
この会社の本社における全社員の勤務時間は、
原則として平日の午前9時から午後6時までと定められています。
昼休憩時間は正午12時から午後1時までの1時間です。
ただし、フレックスタイム制度が適用される部門では、コアタイムを午前10時から午後3時とし、
出退勤時間を各自で柔軟に設定することができます。
遅刻や早退、欠勤を行う場合は、事前に上長の許可が必要とされ、
やむを得ない理由で当日連絡となる場合は、
始業前までに電話または社内チャットで連絡する必要があります。
勤務状況はタイムカードまたは勤怠管理システムで記録され、月末時点で人事部門が確認を行います。
あとは得られた結果を、Web画面に表示することで、類似検索システムや、Q&Aチャットボットの作成ができます。
まとめ
OpenAI Vector Storeを活用したRAGの構築方法についてみてきました。
Vector Storeを使えば、PDFやテキストファイルをアップロードし、自動でベクトル化することで意味に基づく文書検索が可能になります。
ユーザーの質問に対して関連文書を取得し、その文脈をもとにChatGPTが自然な回答を生成できます。
そのため、業務で蓄積された情報を活用したい場面や、社内チャットボットを構築したい場合に非常に有効になります。
今後はAIエージェントとの連携や高度なプロンプト設計も視野に入れることで、さらに多様な使い方ができると思われます。




