
今回は、OpenAI から2025年3月20日に発表された、gpt-4o-transcribe/gpt-4o-mini-transcribeについて、実際に使用しながら確認していきます。
gpt-4o-transcribe/gpt-4o-mini-transcribeの概要
まずは、gpt-4o-transcribe/gpt-4o-mini-transcribeの概要について確認します。
モデルの特徴と主な機能
「gpt-4o-transcribe」と「gpt-4o-mini-transcribe」は、いずれもOpenAIの最新アーキテクチャであるGPT-4o/GPT-4o-miniを音声トランスクリプション向けに発展させたモデルです。
「gpt-4o-transcribe」と「gpt-4o-mini-transcribe」では、以下の特徴を持っています。
①高精度な音声認識
雑音がある環境や複数話者にも対応し、発話内容を正確にテキスト化が可能です。
日本語・英語はもちろん多言語書き起こしが可能です。
②低遅延・ストリーミング対応
“ほぼリアルタイム”で文字起こしできるストリーミング機能があります。
会議のライブ字幕やインタビュー録音などに適した応答速度となっています。
③タイムスタンプオプション
秒単位で「いつ何を話したか」を付与するタイムスタンプ出力が可能です。
※現時点では、whisper-1しか対応していない模様。
技術的イノベーションの背景
OpenAI公式ドキュメントによると、今回の技術的イノベーションの背景は以下の点にあるようです。
①本物の音声データでの事前学習
GPT-4o系の骨格を活かしつつ、音声特化データセットで徹底的にプレトレーニングしています。
そのため、微妙な発音や言い回しのニュアンスを捉え、高い汎用性能を実現しています。
②高度な蒸留(Distillation)手法
大型モデルの知識をより小型モデルへ効果的に転移しています。
自己対話(self-play)で生成した会話データを使い、実際のユーザー対アシスタントのやり取りに近いシナリオで訓練しています。
③強化学習(Reinforcement Learning)パラダイム
音声→テキスト変換タスクに強化学習を多用しています。
誤認識(hallucination)の低減と精度向上を同時に達成し、複雑な会話でも安定した書き起こしが可能となっています。
以上が、今回発表された「gpt-4o-transcribe」と「gpt-4o-mini-transcribe」では行われているようです。
whisperとの比較
OpenAIの音声変換モデルとしては、whisperが存在しましたが、そのモデルよりも精度がかなり向上していることがOpenAI公式資料からわかります。
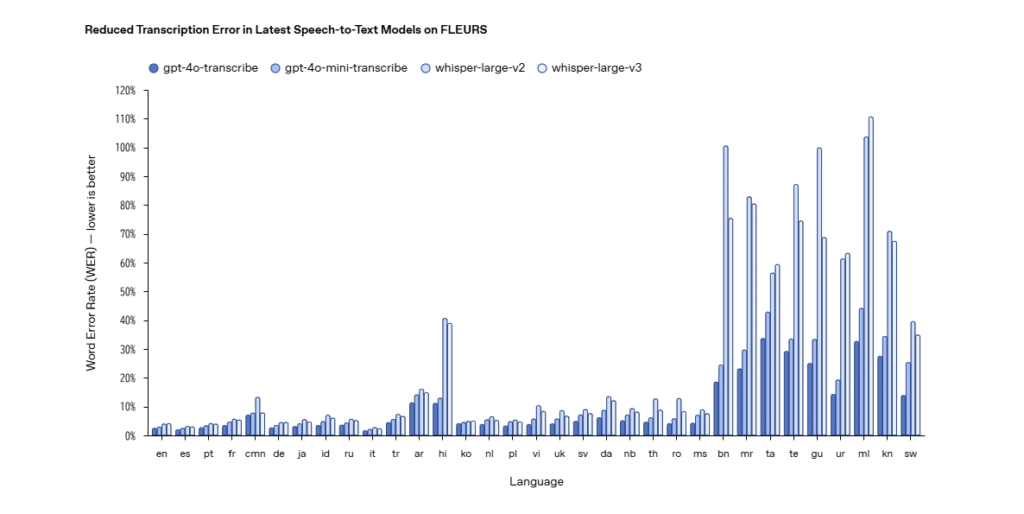
多言語ベンチマーク「FLEURS」において、ほぼ全ての言語でWhisperを上回る結果となっています。
gpt-4o-transcribeの基本的な使い方
それでは、早速gpt-4o-transcribeのAPIを使用していきます。
音声ファイルの読み込み
まずは、基本的な音声ファイを読み込むコードを確認します。
今回は以下のサンプル音声をもとに検証しました。
参照元URL:https://pro-video.jp/voice/announce/
from openai import OpenAI
import os
from dotenv import load_dotenv
# .env ファイルを読み込む
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"),)
audio_file= open("/path/to/file/audio.mp3", "rb")
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file
)
print(transcription.text)必要なライブラリをインポートし、audio_fileに今回呼び出しを行う音声ファイルのパスを入れます。
client.audio.transcriptions.create を呼び出し、file パラメータに先ほど開いた audio_file を渡します。model パラメータに “gpt-4o-transcribe” を指定します。
実行した結果は以下の通りです。
無添加のシャボン玉石鹸ならもう安心。天然の保湿成分が含まれるため肌にうるおいを与え、健やかに保ちます。お肌のことでお悩みの方はぜひ一度、無添加シャボン玉石鹸をお試しください。お求めは0120-0055-95まで。
音声からテキストに変換することができました。
プロンプトによる品質向上
音声に対しての説明プロンプトを追加することで、音声変換の品質を向上させることができます。
from openai import OpenAI
import os
from dotenv import load_dotenv
# .env ファイルを読み込む
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"),)
audio_file= open("001-sibutomo.mp3", "rb")
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
prompt="この音声は、広告の音声です。"
)
print(transcription.text)
promptに説明を追加することができます。
ストリーミング設定
今回はすでに録音が完了したデータのストリーミングについて確認します。
import requests
import os
import json
from dotenv import load_dotenv
# .envファイルから環境変数を読み込む
load_dotenv()
# OpenAI APIキーを取得
api_key = os.getenv("OPENAI_API_KEY")
# APIエンドポイントとヘッダーの設定
url = "https://api.openai.com/v1/audio/transcriptions"
headers = {
"Authorization": f"Bearer {api_key}",
}
# 音声ファイルを開く
with open("001-sibutomo.mp3", "rb") as audio_file:
files = {
"file": audio_file,
}
data = {
"model": "gpt-4o-mini-transcribe",
"response_format": "json",
"stream": "true",
}
# ストリーミングリクエストを送信
with requests.post(url, headers=headers, files=files, data=data, stream=True) as response:
# レスポンスの各行を処理
for line in response.iter_lines():
if line:
decoded_line = line.decode('utf-8')
# 'data: 'プレフィックスを除去
if decoded_line.startswith("data: "):
json_data = decoded_line[len("data: "):]
try:
# JSONデータを解析
event = json.loads(json_data)
# 'delta'キーが存在する場合、値を表示
if event.get("type") == "transcript.text.delta" and "delta" in event:
print(event["delta"], end='', flush=True)
# 'done'イベントが来たらループを終了
elif event.get("type") == "transcript.text.done":
break
except json.JSONDecodeError:
# JSONの解析に失敗した場合は無視
continue公式には、stream=Trueでストリーミングができるように書いてありますが、試したところエラーとなりました。
調査したところ、現在のPython SDKでは stream=True を使用したストリーミングはサポートされていないようで、
ストリーミング機能を利用するには、HTTPリクエストを直接使用する方法があるようです。
また、対応されたら情報を更新しようと思います。
whisperとの実行結果比較
最後に、whisper-1とgpt-4o-transcribeの精度を比較しておきたいと思います。
以下は、Youtubeから2023年2月9日の国会中継を拾ってきたものになります。
whisper-1でテキスト変換した結果
本年10月導入予定の的確請求書 等保存方式インボイス制度について は免税事業者が取引過程から排除 される
不当な値下げ圧力を受ける インボイスの発行保存等のコスト 負担が大きいなどが懸念されています
したがってインボイス制度の廃止 を提案しますが財務大臣いかが ですか
インボイス制度については個人 情報の漏洩問題も指摘されています
国税庁が開設した的確請求書発行 事業者公表サイトで個人情報が 公表されているとの指摘がありました
これを受けて国税庁は個人情報 を非公開とすべく修正しました
しかし非公開としたはずの項目 は実は簡単なプログラムで復元 できるとの指摘があります
財務 大臣事業者公表サイトを即時に 一旦閉鎖することを提案します かやっていただけますか
次にインボイス制度についてお 尋ねがありました
インボイス制度は複数税率の下で 適正な課税を確保するために重要な ものです
ご指摘のような小規模事業者の 方々のさまざまな御懸念について 耳を傾け
政府一体で連携して丁寧 に課題を把握しながらきめ細かく 対応してまいります
具体的には免税事業者をはじめ とした事業者の取引について取引 環境の整備に取り組むとともに
令和4年度補正予算においてインボイス 対応のための支援策の充実を盛り 込んでいます
さらに令和5年度税制改正において はこれまで免税事業者であった 方が
インボイス発行事業者となった 場合の負担軽減措置や奨学のインボイス の保存に関する
中小事業者の事務 負担軽減措置などを講ずること としております
その上で国税庁のサイトにおいて 法令に基づき失礼しました
その上で国税庁のサイトにおいて は法令に基づきインボイス発行 事業者の氏名登録番号
登録年月日 などが掲載されておりますが御 指摘の簡単なプログラムで復元 される項目も
法令で公表することを 定められたものに含まれることから
復元されたことを理由に本サイト を閉鎖することは考えておりません
他方その公表の在り方について は不断に検討してまいりたいと 考えておりますgpt-4o-transcribeでテキスト変換した結果
本年10月導入予定の的確請求書等保存方式インボイス制度については、免税事業者が取引過程から排除される、
不当な値下げ圧力を受ける、インボイスの発行保存等のコスト負担が大きいなどが懸念されています。
したがって、インボイス制度の廃止を提案しますが、財務大臣いかがですか。
インボイス制度については、個人情報の漏洩問題も指摘されています。
国税庁が開設した的確請求書発行事業者公表サイトで個人情報が公表されているとの指摘がありました。
これを受けて国税庁は個人情報を非公開とすべく修正しました。
しかし、非公開としたはずの項目は実は簡単なプログラムで復元できるとの指摘があります。
財務大臣、事業者公表サイトを即時に一旦閉鎖することを提案しますか、やっていただけますか。
次にインボイス制度についてお尋ねがありました。
インボイス制度は複数税率の下で適正な課税を確保するために重要なものです。
ご指摘のような小規模事業者の方々の様々な御懸念について耳を傾け、
政府一体で連携して丁寧に課題を把握しながらきめ細かく対応してまいります。
具体的には免税事業者をはじめとした事業者の取引について、取引環境の整備に取り組むとともに、
令和4年度補正予算においてインボイス対応のための支援策の充実を盛り込んでいます。
さらに令和5年度税制改正においては、これまで免税事業者であった方が
インボイス発行事業者となった場合の負担軽減措置や、小額のインボイスの保存に関する
中小事業者の事務負担軽減措置などを講ずることとしております。
その上で国税庁のサイトにおいて法令に基づき、インボイス発行事業者の氏名、登録番号、
登録年月日などが掲載されておりますが、ご指摘の簡単なプログラムで復元される項目も
法令で公表することを定められたものに含まれることから、
復元されたことを理由に本サイトを閉鎖することは考えておりません。
他方、その公表のあり方については不断に検討してまいりたいと考えております。
whisper-1で一部あった誤字が解消されており、また文書の句読点もついており、gpt-4o-transcribeの方が精度が良いことがわかりました。
ただ、「適格請求書」といった専門用語までは、変換できないようです。
専門用語は、プロンプトなどで変換していく必要がありそうです。
まとめ
今回は、gpt-4o-transcribe/gpt-4o-mini-transcribeの具体的な使用方法について確認しました。
音声→テキスト変換は、会議の議事録自動作成やプレゼン発表自動文字おこしなど、できると業務効率につながる技術だと考えます。
gpt-4o-transcribe/gpt-4o-mini-transcribeではまだ、話者区別ができない、専門用語の認識ができないなど問題もあります。
ただし、音声認識精度は昔に比べ格段と上がっていますので、積極的に活用していきたいです。





