
フリーランスエンジニアのまさです。
この記事では、Langgraph Studioの基本的な使い方を見ていこうと思います。
LangGraphはAI Agentを開発するのに非常に適したライブラリですが、各エージェントやエッジなどを視覚的に表現してくれるのが、Langgraph Studioになります。
Langgraph Studioによって、LangGraphによるAIエージェントの開発が効率化すると考えられるため、積極的に使っていきたいと思います。
まずは、環境の構築から簡単な操作方法などを確認します。
それでは早速見ていきましょう。
Langgraph Studioの概要
LangGraph Studioは、LangChainフレームワークの一部であるLangGraphを用いて、複雑なエージェントアプリケーションを視覚的に構築、デバッグ、そして管理するための統合開発環境(IDE)です。
このツールは、エージェントのワークフローをグラフ形式で視覚化し、各ステップの実行状況をリアルタイムで確認できる機能を提供します。
そのため、開発者はエージェントの構造を直感的に理解し、コードの改修やプロンプトの調整などが可能となります。
LangGraph Studioの主な特徴
LangGraphの主な特徴は以下の通りです。
コードの視覚化
LangGraphで作成したアプリケーションの構造をグラフとして直感的に表示することができます。
LangGraphでは、マークダウンなどでグラフを表示することも可能ですが、グラフ自体の拡大縮小などもでき非常に見やすくなっています。

インタラクティブな実行
Inputに情報を入れて実行すると、各ノードの動作をリアルタイムで確認することができます。
そして、各ノードの結果についても全て確認することができます。
スレッド管理
複数の実行スレッドを作成・管理できます。
プロンプトの入力内容による結果の比較などに役立てることができます。

インタラプト機能
実行中のグラフを特定のポイントで一時停止し、ステップバイステップでの実行が可能です。
思うような結果が出力されない際、どのノードで問題が発生しているか確認したり、各ノードから出力された結果をトレースするのにも役立ちます。
Langgraph Studioの構築
Langgraph Studioの構築について、ローカル環境での構築とLangGraph Cloudにデプロイして使用する方法があります。
今回は、ローカル環境での実行を試していきます。
環境構築
Langgraph Studioを使用するためには、Python 3.11以上がインストールされている必要があります。
使用しているpythonバージョンを確認してください。
LangGraph CLIのインストールを行います。
pip install -U "langgraph-cli[inmem]>=0.1.55"girリポジトリからクローンを行い、コピー先のフォルダに移動します。
git clone https://github.com/langchain-ai/langgraph-example.git
cd langgraph-exampleフォルダ構成は以下の通りになっています。

環境変数を設定していきます。
.env.exampleファイルを.envに変更し、必要なAPIキーを入力していきます。
ANTHROPIC_API_KEY=...
TAVILY_API_KEY=...
OPENAI_API_KEY=...仮想環境を立ち上げ、プロジェクトディレクトリ(langgraph.jsonが存在する場所)に移動します。
以下のコマンドを実行してサーバーを起動します。
langgraph devサーバーが正常に起動すると、以下のようなメッセージが表示されます。
Ready!
LangGraph Studio Web UI: https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024ブラウザが自動で開き、LangGraph Studioに接続します。
自動で開かない場合は、表示されたURLにアクセスすることでLangGraph Studioに接続します。
それにより、ローカルで実行されているエージェントを視覚化、操作、デバッグすることができます。

Langgraph Studioの使用感
gitに上がっていたコードから以前Langgraphの検証で使用したコードに変更して、LanggraphStudioで表示してみました。
agent.pyのコードを以下に修正
from langgraph.graph import StateGraph, END
from my_agent.utils.nodes import selection_node, search_perplexity, database_search_employee, result_summary
from my_agent.utils.state import AgentState
# 新しいグラフを定義
workflow = StateGraph(AgentState)
# ノードを定義
workflow.add_node("selection", selection_node)
workflow.add_node("search_perplexity", search_perplexity)
workflow.add_node("database_search_employee", database_search_employee)
workflow.add_node("result_summary", result_summary)
# エントリーポイントを selection に設定
workflow.set_entry_point("selection")
# エッジの定義
workflow.add_conditional_edges(
"selection",
lambda state: state.current_role, # リスト
{
"1": "search_perplexity",
"2": "database_search_employee"
},
)
workflow.add_edge("search_perplexity", "result_summary")
workflow.add_edge("database_search_employee", "result_summary")
workflow.add_edge("result_summary", END)
# コンパイルの実施
graph = workflow.compile()
state.pyのコードを以下に修正
from pydantic import BaseModel, Field
from typing import Annotated
import operator
class AgentState(BaseModel):
query: str = Field(..., description="ユーザーからの質問")
current_role: str = Field(
default="", description="選定された回答ロール"
)
answers: Annotated[list[str], operator.add] = Field(
default=[], description="回答履歴"
)nodes.pyのコードを以下に修正
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import ToolNode
from langchain_core.runnables import ConfigurableField
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from typing import Any
from openai import OpenAI
llm = ChatOpenAI(model="gpt-4o", temperature=0.0)
llm = llm.configurable_fields(max_tokens=ConfigurableField(id='max_tokens'))
def selection_node(state) -> dict[str, Any]:
query = state.query
prompt = ChatPromptTemplate.from_template(
"""質問を分析し、最も適切なエージェントを選択してください。
### 選択肢
1.web検索エージェント:AIがWeb検索を行い、最適な情報を提供します。
2.社員情報検索エージェント:該当の技術スタックに精通する社員を検索し、その情報を提供する。
### 質問
{query}
### 出力形式
回答は選択肢の番号(1または2)のみを返してください。
""".strip()
)
# 選択肢の番号のみを返すことを期待したいため、max_tokensの値を1に変更
chain = prompt | llm.with_config(configurable=dict(max_tokens=1)) | StrOutputParser()
role_number = chain.invoke({"query": query})
return {"current_role": role_number}
def search_perplexity(state) -> dict[str, Any]:
"""2024年の時点の最新の情報をウェブ検索する関数"""
query = state.query
messages = [
{
"role": "system",
"content": (
"You are an artificial intelligence assistant and you need to "
"engage in a helpful, detailed, polite conversation with a user."
),
},
{
"role": "user",
"content": (
query
),
},
]
client = OpenAI(api_key="xxxx", base_url="https://api.perplexity.ai")
response = client.chat.completions.create(
model="llama-3.1-sonar-large-128k-online",
messages=messages,
)
answer = response.choices[0].message.content
return {"answers": [answer]}
def database_search_employee (state) -> dict[str, Any]:
"""社員情報検索を実行する関数"""
query = state.query
# 本来は検索機能を実装するべきだか、ここではダミーデータが返ってきたことを想定
search_result = """Aさん
- 生産管理システムの最適化
- 生産ラインの稼働状況をリアルタイムで監視するダッシュボードの開発
- AIを活用した生産計画の自動化と効率化
- 現場スタッフ向けの使いやすいモバイルアプリの設計・導入
Bさん
- 製品検査プロセスのデジタル化
- 画像認識技術を活用した自動検査システムの構築
- データ解析による不良品の原因分析と予防策の提案
- 検査結果の可視化ツールを用いた品質管理レポートの作成
Cさん
- IoTを活用した工場のスマート化推進
- センサーデータを活用した設備稼働状況の予測分析
- クラウドプラットフォームによる生産データの一元管理
- 設備保全のためのAI予測保全モデルの導入"""
prompt = ChatPromptTemplate.from_template(
"""あなたは社員情報検索エージェントです。以下の社員情報を元にユーザの質問に回答してください。
### 社員情報
{search_result}
### 質問
{query}
""".strip()
)
chain = prompt | llm | StrOutputParser()
answer = chain.invoke({"search_result": search_result,"query": query})
return {"answers": [answer]}
def result_summary(state) -> dict[str, Any]:
"""前のノードで得られた結果を統合するノード"""
summary = f"Question: {state.query}\nAnswer: {state.answers[-1]}"
return {"answers": [summary]}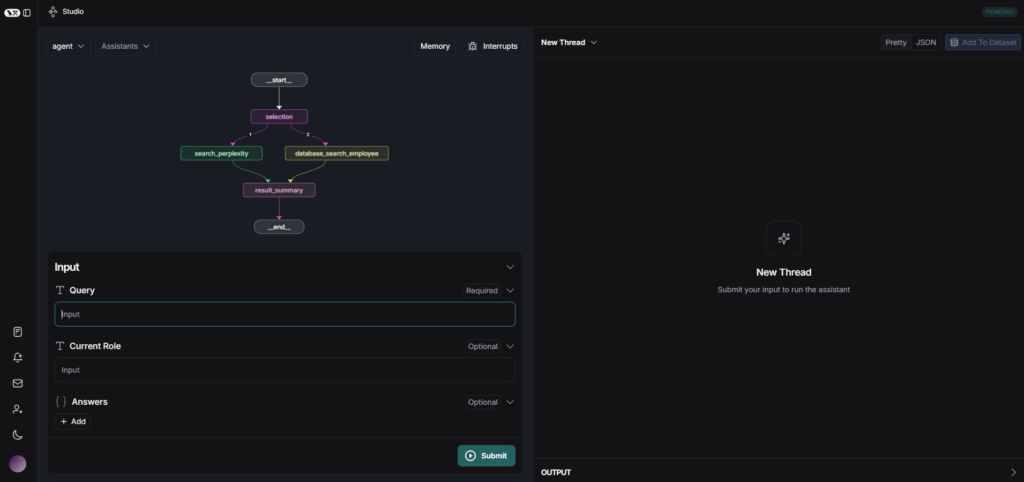
プロンプト:「2025年現在の日本の総理大臣の名前を教えてください。」
上記プロンプトを実行すると、__start__→selection→search_perplexity→result_summaryの順で実行され、結果が正しく出力されました。

プロンプト:「製品検査プロセスのデジタル化が得意な社員を教えてください。」
上記プロンプトを実行すると、__start__→selection→database_search_employee→result_summaryの順で実行され、結果が正しく出力されました。

まとめ
今回は、Langgraph Studioをローカル環境で構築し使用してみました。
Langgraph Studioは、複雑なマルチエージェントシステムを構築する際に非常に効率的に開発ができると考えています。
各ノードの出力を確認し、どのノードで想定と異なる出力がされているのか特定しやすくなっています。
また、インタラプト機能でステップ実効的なこともできるようになっているため、デバッグしやすいのも非常に良い点と感じました。
AIエージェントについては、今後も注目される技術課と思いますので、引き続きLanggraphについて、学習を進めていきます。





