
フリーランスエンジニアのまさです。
リレーショナルデータベース上でもベクトルデータを扱いたい
ベクトルデータベースを活用した類似検索を行いたい
この記事では、リレーショナルベースのPostgreSQLにある拡張機能pgvectoを活用して、テキストデータの類似検索を実現する方法について詳しく解説します。
PostgreSQLの設定から、OpenAIのembeddingモデルを用いて、PostgreSQLのデータをベクトル検索する方法を紹介します。
それでは順にみていきましょう。
インストール作業
まずは、PostgreSQLのインストールを行い、拡張機能であるpgvectorのインストールを実施します。
PostgreSQLのインストール
PostgreSQL を Windows にインストールする手順については以下のサイトを参考に実施しました。(PostgreSQLインストール手順は今回のメインテーマでないため説明は割愛します)
PostgreSQL を Windows にインストールするには
今回は、postgresql16.3をインストールして検証を実施しました。
pgvectorのインストール
postgresqlのインストールが完了したら、次は、pgvectorのインストールと設定を行います。
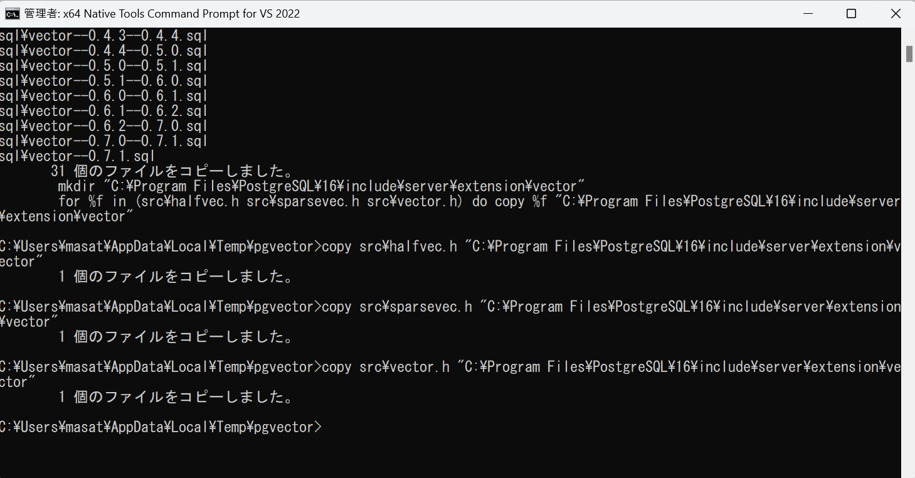
x64 Native Tools Command Promptを管理者権限で開き、以下のコマンドを実施します。
set "PGROOT=C:\Program Files\PostgreSQL\16"
cd %TEMP%
git clone --branch v0.7.1 https://github.com/pgvector/pgvector.git
cd pgvector
nmake /F Makefile.win
nmake /F Makefile.win install実行すると以下のようになります。
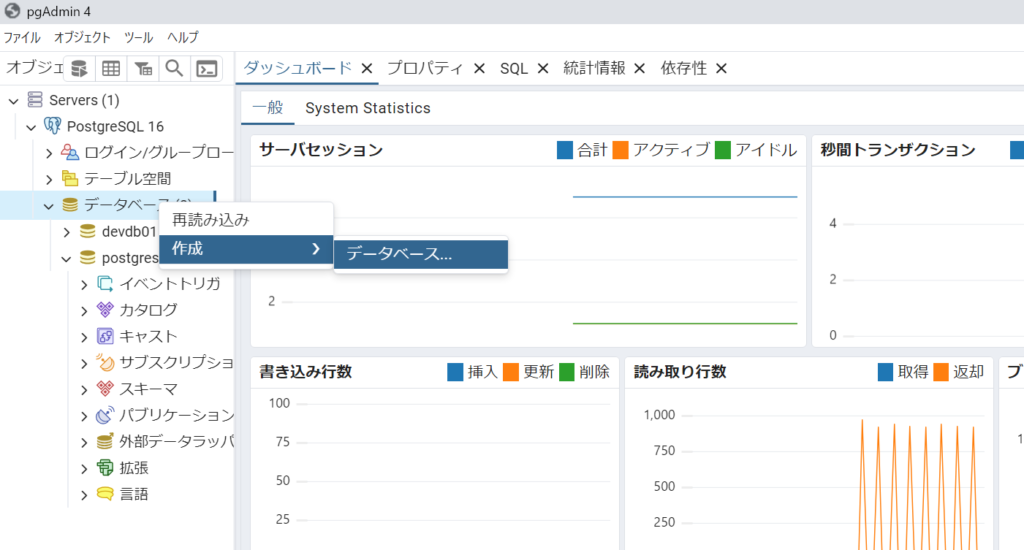
pgAdmin4を開き、データベースの作成を実施します。
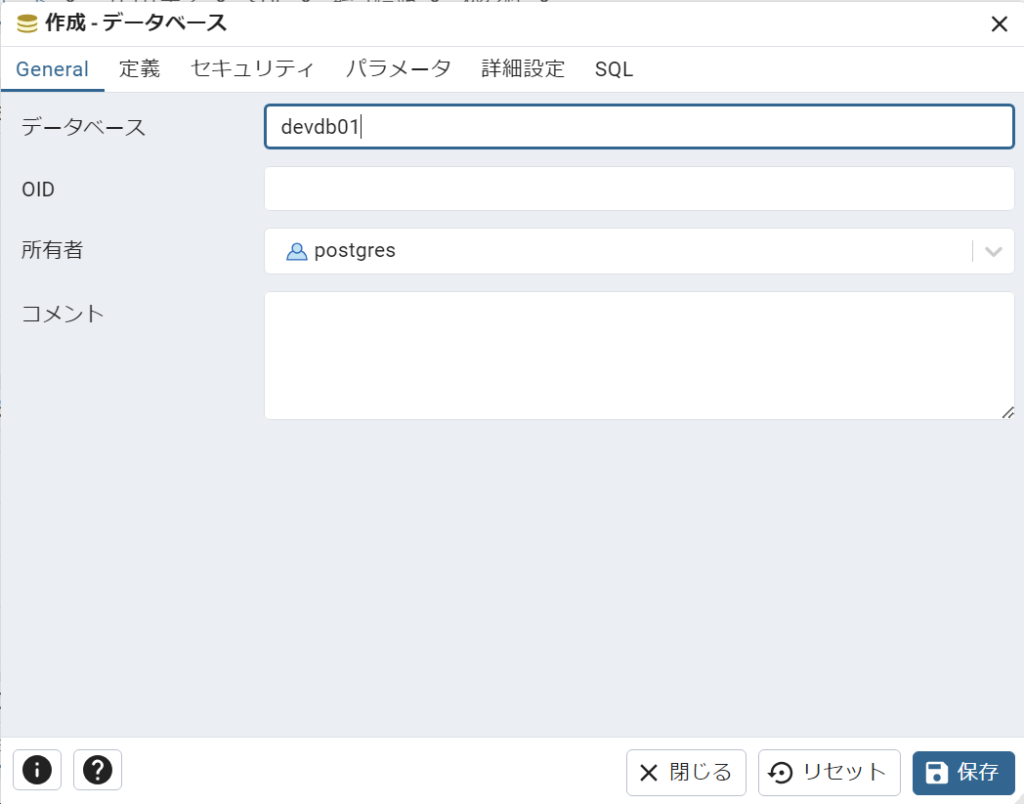
devdb01という名前で検証用のデータベースを作成します。
(今回は「定義」「セキュリティ」「パラメータ」「詳細設定」タブについては特に設定はしません)
データべースの作成が完了したら、データベースを選択し、「クエリツール」を選びます。
そして、以下のコマンドを実行します。
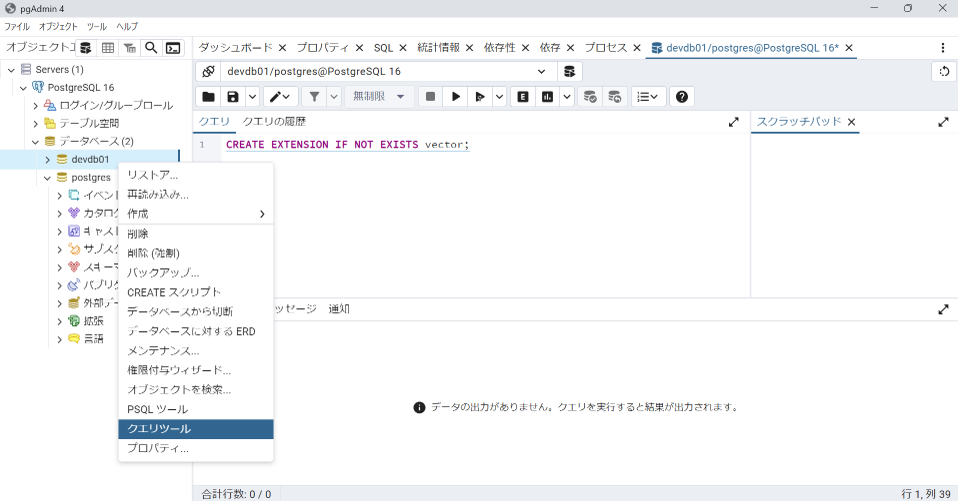
CREATE EXTENSION IF NOT EXISTS vector;メッセージにCREATE EXTENSIONと表示されれば成功です。
これで、pgvectorのインストールは完了です。
テーブルの作成/データのインポート
次に、テーブルの作成を実施します。
今回は、以下のデータを後ほどインポート予定ですので、それに合わせてテーブルの型を定義します。

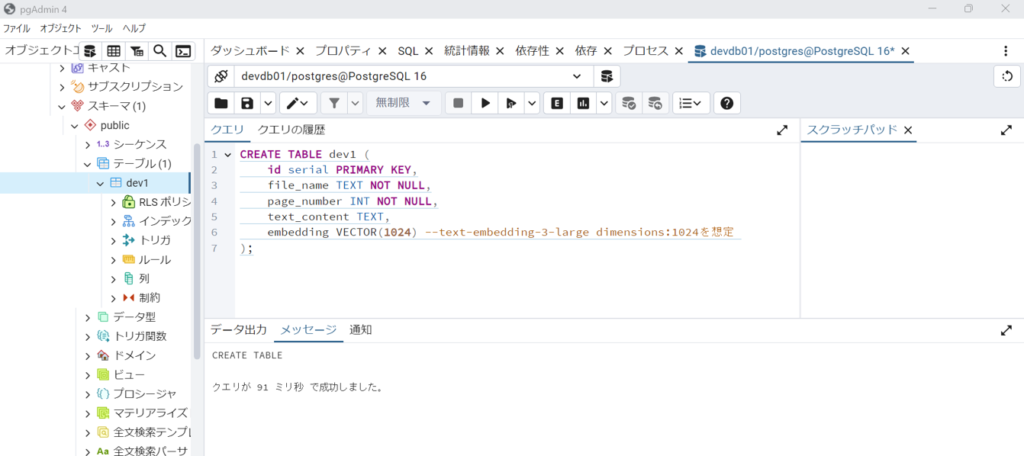
クエリに以下のコマンドを入力してテーブルの作成を実施します。
CREATE TABLE documents (
id serial PRIMARY KEY,
file_name TEXT NOT NULL,
page_number INT NOT NULL,
text_content TEXT,
embedding VECTOR(1024) -- 1024次元のベクトルデータ
);
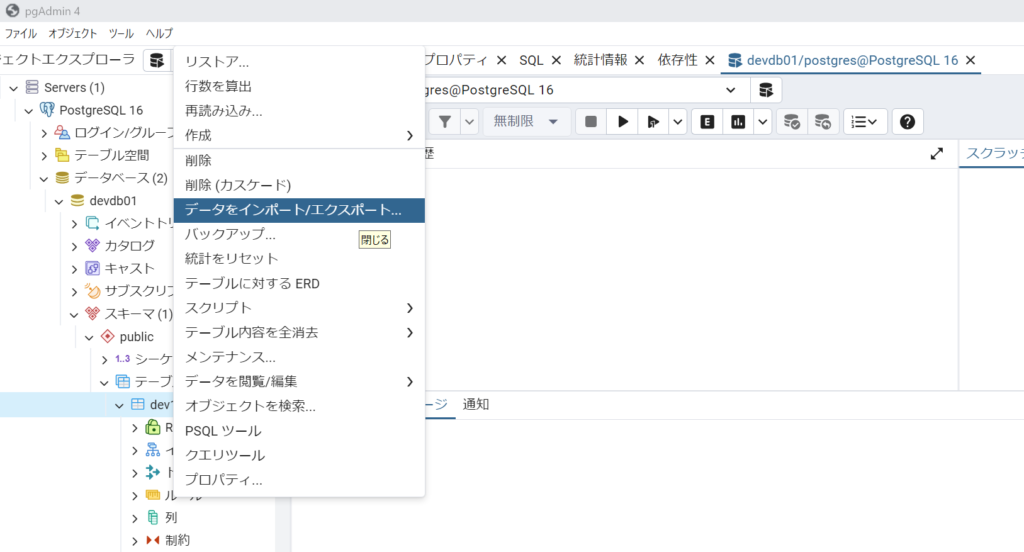
テーブルの作成が完了したら、次は、データのインポートを実施します。
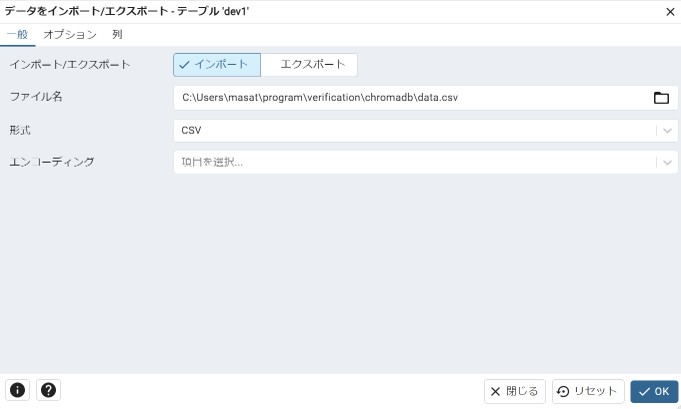
データのインポートについては、テーブルを選択→データをインポート/エクスポートから実行できます。
データのインポート/エクスポート画面から対象のcsvファイルを選択して、インポートを実施します。
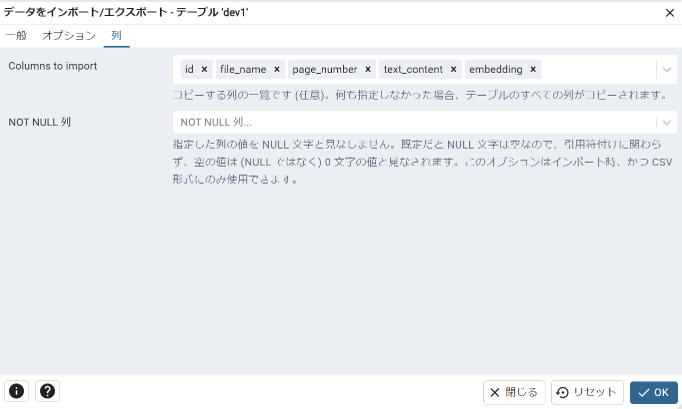
インポートが完了したら、データが問題なく格納されているか確認しましょう。
SELECT * FROM テーブル名
ORDER BY id ASC LIMIT 100これで、類似検索の準備は完了です。
類似検索の実施
最後に、インデックスの作成を実施します。
インデックスの役割としては、検索速度の向上、クエリパフォーマンスの改善、ソートと集計の効率化などがあげられますが、今回は、高次元ベクトルデータに対する近似最近傍検索を高速化するために実施します。
要は、ベクトル検索を高速化するために実施し、特定のベクトルに最も近いベクトル(類似ベクトル)を迅速に見つけるようにします。
テーブルのクエリーから以下のコマンドを実行します。
CREATE INDEX ON dev1 USING hnsw (embedding vector_cosine_ops);上記コマンドについて少し解説します。
pgvectorでは2種類のインデックス(HNSW,IVFFlat)が利用可能になっています。
それぞれ以下の特徴があります。
| HNSW | IVFFlat | |
| 構造 | グラフベースのデータ構造で、高次元ベクトル空間における近似最近傍検索を効率的に行う | ベクトルデータをクラスタリングし、各クラスタに対してフラット(線形)検索を行う |
| 特徴 | ・高い精度で近似検索を行うことができる ・検索速度が非常に速い ・新しいデータポイントを効率的に追加可能 | ・大規模データセットに対しても効率的に動作 ・検索対象をクラスタに絞り込むことで、検索速度が向上 ・精度と検索速度の間でトレードオフが可能 |
今回は、HNSWを使用してインデックスを作成します。
そして、pgvectorには複数の距離関数が用意されています。
| 関数 | 説明 |
| vector_cosine_ops | コサイン類似度 |
| vector_l2_ops | ユークリッド距離 |
| vector_ip_ops | 内積 |
| vector_l1_ops | マンハッタン距離(L1ノルム) |
| vector_linf_ops | チェビシェフ距離(L∞ノルム) |
今回は、類似度検索によく使用されるコサイン類似度を使用して検証を行っていきます。
ここまでで、pgAdmin4の操作は完了です。
次は、pythonコードでデータベースに格納したデータの検索を行います。
今回は、類似度検索によく使用されるコサイン類似度を使用して検証を行っていきます。
ここまでで、pgAdmin4の操作は完了です。
次は、pythonコードでデータベースに格納したデータの検索を行います。
まずは、必要なライブラリのimportから実施します。
import os
from openai import OpenAI
import psycopg2
import pandas as pd
from dotenv import load_dotenv
# import time
# .envファイルを読み込み
load_dotenv()次に、入力情報をembeddingする関数を作成します。
embeddingモデルとしては、OpenAIの「text-embedding-3-large」を使用しています。
(OPENAI_API_KEYは外部の.envファイル記載しています)
client = OpenAI(
api_key = os.getenv("OPENAI_API_KEY")
)
def get_embedding(text):
response = client.embeddings.create(
model="text-embedding-3-large",
input=text,
dimensions=1024
)
return response.data[0].embedding作成した関数に、検索クエリーを入れ関数を実行すると、埋め込みベクトルが返ってきます。
クエリ埋め込みベクトルをデータベース内のベクトルと比較して、類似度を計算するために整形を実施します。
query_text = "職域における資産形成に関する取組について教えてください"
query_embedding = get_embedding(query_text)
# クエリ埋め込みを正規化
query_embedding_norm = np.linalg.norm(query_embedding)
query_embedding_normalized = query_embedding / query_embedding_norm
# クエリ埋め込みを文字列形式に変換
query_embedding_str = ','.join(map(str, query_embedding_normalized))最後に、PostgreSQLへ接続し、SQLクエリを実行することで、類似文章を取得することができます。
# PostgreSQLへの接続
conn = psycopg2.connect(
dbname="devdb01",
user="postgres",
password="admin123",
host="localhost",
port="5432"
)
cur = conn.cursor()
# コサイン類似度計算のSQLクエリ
query = f"""
SELECT id, file_name, page_number, text_content, embedding <=> '[{query_embedding_str}]' AS similarity
FROM dev1
ORDER BY similarity ASC
LIMIT 10;
"""
cur.execute(query)
rows = cur.fetchall()
# カラム名を取得
colnames = [desc[0] for desc in cur.description]
# 結果をデータフレームに変換
df = pd.DataFrame(rows, columns=colnames)上記検証と合わせて、インデックスあり、なしの場合で検索時間を図りました。
インデックスなし:検索時間:0.12秒
インデックスあり:検索時間0.1秒
データ件数が500件前後と少なかったこともあり、インデックス有り無しであまり大差ない結果となってしまいましたが、件数が多くなるにつれて、インデックスがないと検索時間がかかることになるかと思われます。
まとめ
今回は、PostgreSQLのpgvectorを用いた類似検索の検証をを行いました。
リレーショナルデータベース上で、ベクトルデータを格納できるというのは、非常に便利です。
RAGシステム構築の際に、ベクトル検索の結果+必要な情報を出力するということが可能になるため、リレーショナルデータベースを使用いているシステムで活用されそうです。





